
2020年度のひなどりクラスタ
こんにちは!横田研のサーバ管理係です。
横田研では「ひなどりクラスタ」と呼ばれる計算機クラスタをサーバ管理係(鯖缶)の学生が中心となって構築・運用しています。
本記事ではこのひなどりクラスタがどう構築され、どう管理されているかを紹介します。
ひなどりクラスタの構成
横田研では、多数のスーパーコンピュータを利用することができますが、その他にも研究室で運用する「ひなどりクラスタ」があります(ホームページでの紹介)。
現在のひなどりクラスタは以下に示す17ノード・計52GPUsのコンピュータで構成されています。
| CPU | GPU (1ノードあたりの搭載数) | Host Mem | 台数 |
|---|---|---|---|
| AMD EPYC 7402 | NVIDIA GeForce RTX 3090 (8) | 512GB | 3 |
| AMD EPYC 7302 | NVIDIA A6000 (2) | 256GB | 1 |
| AMD EPYC 7742 | NVIDIA A100 SXM4 (8) | 1TB | 1 |
| Intel Xeon Silver 4215 | NVIDIA GeForce GTX 1080Ti (2) | 96GB | 4 |
| NVIDIA GeForce RTX 2080 (2) | 2 | ||
| NVIDIA GeForce RTX 2080Ti (2) | 1 | ||
| NVIDIA TITAN V (2) | 1 | ||
| NVIDIA TESLA V100 PCIe 16GB (1) | 1 | ||
| Intel Xeon E5-2630v3 | NVIDIA TITAN RTX (1) | 64GB | 1 |
| AMD EPYC 7502 | - | 512GB | 1 |
| AMD EPYC 7252 | - | 64GB | 1 |
(2021.03.20現在)
他にも、SSHの踏み台となるログインノード、可用48TBのファイルサーバ、研究室独自のVPNサービスなどを提供しています。
また、これに加えIntel KNL搭載ノードやPEZY SC2搭載ノードも保有しており、特殊なプロセッサについても研究が行われています。
各ノード間は10GbEやInfiniBand HDRで接続されています。

▲ネットワーク構成

▲ひなどりクラスタ

▲RTX3090x8ノード
また、計算ノードがサポートするIPMIにより、わざわざサーバ室へ行かなくともノードの強制シャットダウン・起動ができます。 これによって、例えば東工大の計画停電への対応も、リモートから行え非常に便利です。
運用
Slurmをベースとしたジョブスケジューリング
ジョブスケジューリングにはSlurm Workload Managerを用いています。
SlurmではGRES (Generic RESource)を用いることでジョブに割り当てるGPU数の制御が可能です。
ひなどりクラスタではSlurmに加え独自の計算資源管理ツールであるyokota-rnsを用いることで、簡単にジョブの投入が可能です。
開発環境
CUDA関係や各種コンパイラはEnvironment Modulesで管理されており、好きなバージョンを指定して使うことができます。
標準的なアプリケーション以外にも、プログラムの実行中にGPUの温度や消費電力などを記録していく独自のアプリケーションの提供も行っています。
監視基盤
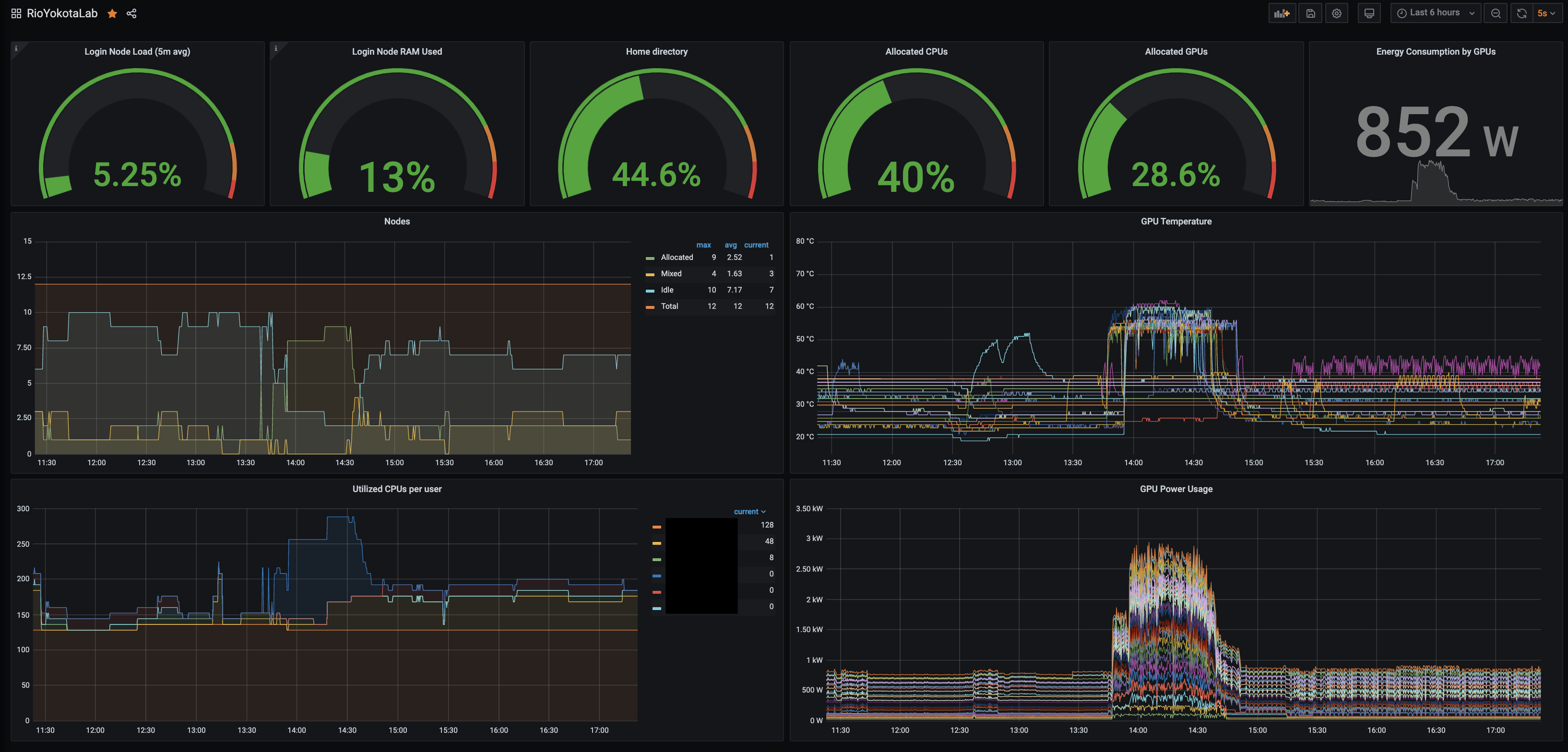
Prometheusによるメトリクスの集約、Grafanaによるメトリクスの可視化を行っています。
監視している主なメトリクスには、CPU使用率やGPU使用率といった性能最適化に利用できるものや、ひなどりクラスタの利用履歴やGPUの温度、消費電力など管理者による監視に必要なものがあります。
ユーザは様々な情報にブラウザ経由でアクセスできます。
Ansibleによる環境の統一
ノードのセットアップはAnsibleを用いて行っています。
これにより全ノードでインストールされているパッケージのバージョンを揃えられる他、
新たにノードをクラスタに追加する場合もOSのインストールから30分程度で利用可能となります。
構築
旧クラスタからの引っ越し
旧クラスタの問題点
2019年度の横田研クラスタはデスクトップPCが棚に並んでいるもので、単に「横田研クラスタ」と呼ばれているものでした。

▲旧横田研クラスタ
しかし、運用を続けていく上で次の問題が出てきました:
- デスクトップ型はかさばるため、物理的にスペースが足りない
- 部屋の電源容量が足りない
これにより、これ以上ノード数・GPU数を増やすことが困難になりました。
TSUBAME 2.5のテープライブラリの撤去と準備
横田研と同じ建物にTSUBAME 2.5で利用されていたテープライブラリが置かれている部屋がありました。 既に使われていなかったため、これを撤去し、横田研で利用させていただくこととなりました。 この部屋は広さも電源容量も十分で、窓もなく、大型の冷房が5機あることから、サーバルームとして利用するにはもってこいの環境です!
さらに、ちょうどTSUBAME 2.5関連で不要となった42Uサーバラック(+PDU)も8台いただくこともできました。 横田研がGSICで良かったです。

▲TSUBAME2 テープライブラリ
この部屋を利用するにあたり、高速なネットワーク接続を確保する必要があります。 テープライブラリで利用されていた建物内のファイバーは折れてしまっているのか使うことができませんでした。 そこで新たに工事を行い、引いてもらうこととなりました。
部屋とラックとネットワークが手に入ったので、いよいよ引っ越しです。
デスクトップ型サーバから1Uサーバへの移行
引っ越しでは、デスクトップ型のサーバからグラフィックスボード(グラボ)を取り外し、別途購入した1Uのシャーシに詰め替えていきました。
詰替えは滞りなくいったのですが、GPUが十分に冷却されないという問題が起きました。
1Uシャーシは内部の空気の流れが悪いことが原因のようです。
そこで、シャーシの蓋を外してしまうとか蓋を切断するとかいろいろな対応を考えました。
結局シャーシには手を加えず、グラボのファンの回転数をソフトウェア的に増加させることで対応しました。
しかし、これはcoolbitsをいじる方法なのですが、この方法ではnvidia-smi時にXorgのプロセスが表示されてしまいます。
これが非常に気に食わないです。
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 2655 G /usr/lib/xorg/Xorg 8MiB |
| 1 N/A N/A 2656 G /usr/lib/xorg/Xorg 8MiB |
| 2 N/A N/A 2657 G /usr/lib/xorg/Xorg 8MiB |
| 3 N/A N/A 2658 G /usr/lib/xorg/Xorg 8MiB |
| 4 N/A N/A 2659 G /usr/lib/xorg/Xorg 8MiB |
| 5 N/A N/A 2660 G /usr/lib/xorg/Xorg 8MiB |
| 6 N/A N/A 2661 G /usr/lib/xorg/Xorg 8MiB |
| 7 N/A N/A 2662 G /usr/lib/xorg/Xorg 8MiB |
+-----------------------------------------------------------------------------+
そこでnvidia-smiをnvidia-smi | grep -v Xorgで置き換えることで、Xorgを消すことに成功しました(笑)。
ジョブスケジューリングの効率化
引越しに伴いジョブスケジューリングも効率化しました。
以前の横田研クラスタでも今と同じSlurmを用いていたのですが、ジョブあたりのGPU割当数の制御はできませんでした。
これは、例えば1GPUしか使わないジョブであっても4GPU搭載したノードを占有するということが起きており、3GPUは使われないという悲しく勿体ない状況が起きていました。
このため引っ越しを機にSlurmのGRES (General RESource)の設定を行い、搭載GPU数でノードの計算資源を分割し、複数のジョブを1ノードに割り当てられるようにしました。
副産物として、GRESの設定を自動で生成するスクリプトが生まれました。
これを使うとひなどりクラスタのようにノード毎に搭載されているGPU数が異なる環境でもAnsibleによるGRESのセットアップが簡単に行えます。
enp1s0 / SLURM GRES config generator - GitHub
GRESの設定はできましたが、これをユーザに使ってもらうにはジョブに必要なCPUコア数やGPU数をジョブスクリプトに書いてもらう必要があります。
これは少し面倒なことですし、記述ミスにより思うように計算資源を取れないのは良いことではありません。
そこで、この問題を解決し簡単にミスなくジョブを投入できるよう、横田研独自の資源管理拡張yokota-rnsを作成しました。
yokota-rnsを用いた場合、
#!/bin/sh
#YBATCH -r dgx-a100_1
#SBATCH -N 1
...
のように#YBATCH -rを用いて資源名を指定します。
このジョブスクリプトをybatchコマンドで投入すると、資源名をCPUコア数やGPU数を指定する#SBATCHに翻訳し、ジョブが投入されます。
インタラクティブジョブも
yrun dgx-a100_2
でDGX A100上で2GPU分の資源を確保することができます。
squeueコマンドもyokota-rns用にいじっており、ジョブ投入時に指定した資源名を見ることができるようになっています(RESOURCEの列)。
JOBID PARTITION NAME USER ST TIME NODES RESOURCE NICE NODELIST
5104 dgx-a100 XXXXXXXX XXXXXXXX R 1-07:36:35 1 dgx-a100_1 0 dgx-a100
5116 titanrtx XXXXXXXX XXXXXXXX R 1-04:36:20 1 titanrtx 0 titanrtx
5134 dgx-a100 XXXXXXXX XXXXXXXX R 1-03:05:27 1 dgx-a100_1 0 dgx-a100
5165 titanv XXXXXXXX XXXXXXXX R 5:35:52 1 titanv_2 0 titanv
5167 am XXXXXXXX XXXXXXXX R 1:04:06 1 am_8 0 am-02
その他にもsgpuinfoコマンドにより、各ノードの利用可能GPU数を見ることができます。
Node AvailGPUs TotalGPUs
psti-01 2 2
psti-02 2 2
psti-03 2 2
psti-04 2 2
tr-01 2 2
tr-02 2 2
titanv 0 2
teslav 1 1
titanrtx 0 1
trti 2 2
a6000 2 2
am-01 8 8
am-02 0 8
am-03 8 8
dgx-a100 6 8
新ノードの調達
現在のひなどりクラスタのうち、CPUがAMD社製のノードは今年度新たに調達したノードです。 ノードの調達は2020年9月頃から開始し、2021年2月納品のスケジュールで行いました。
調達の流れについて説明しておきましょう。
横田研では、深層学習に関連する研究テーマが多く、現在発売されているGPUの中ではRTX 3090が最も良さそうなことが事前の調査から分かっていました。
そこで、RTX 3090とPCIe 4.0を活用するべく、AMD EPYC (Rome)を基本とする仕様を検討することにしました。
その後業者さまとコンタクトを取り、冷却テストを行ってもらうなど仕様を練る作業を続けていきます。
仕様が決定したら、それをもとに入札用の仕様書を作成します。
仕様書では具体的なパーツの型番を書くことはできないため、現在想定するワークロードで必要となる仕様をパーツの仕様から抽出していきます。
横田研は比較的新しい研究室であるため、仕様書作成のノウハウはほぼなく、この作業は難しかったです。
入札結果を見ると、仕様書の不備で想定と違った性能になった箇所もありました。
しかしながら、基本的には問題なく納品いただき、現在横田研の研究へ役立てられています。
計算ノードの他に、InfiniBand HDRスイッチの調達も行いました。 横田研での使用用途ですと、より安いRefurbished品(整備済み品)でも問題がなく、業者の方にご尽力いただき安く調達することができました。 ありがとうございます。
新ノードの納品が終わったらAnsibleによるセットアップです。
自分でplaybook/rolesを作っておいてなんですが、本当に30分程度でセットアップが終わって感動です。
新たにノードを追加していくと、電源容量が大きな部屋に引っ越したにもかかわらず電源が足りなくなることが分かりました。 幸いにも今回は簡単な工事で電源を増やすことができましたが、今後更にノードが増えるとどうなることやら。。。
ノードの負荷テスト
横田研ではGPUの負荷テストとしてATSUKANと呼ばれるテストを行います。
鯖缶の1人は趣味でGPUの排熱を用いて熱燗を作っており、この際に用いているプログラムを使ったテストです。
このテストにパスすると、認定シールが貼られます。
これにより、横田研の学生は安心してGPUに負荷をかけるプログラムを実行することができます。

DGX A100はかなり冷却性能は高いです。
(かわりに結構音がうるさく、サーバ室に二重扉をつける防音工事をしました)
DGX A100に限った話ではありませんが、すごく発熱するのにそれをすべて空気中に廃棄するなんてとてももったいないですね。

ノード利用サポート
講習会
先日ひなどりクラスタの使い方の講習会としてGPU談笑会なるものを開催しました。
談笑会では、使用するGPUの選び方について丁寧に説明をしました。
鯖缶はニコニコ話をしましたが、オンラインで行ったため他の人たちが談笑していたかは(?)
オタクが早口で話をしているだけの会ではなかったことを祈っています。
Slack
ひなどりクラスタに対する質問、要望、またクレーム(?)は随時研究室Slackで鯖缶が対応しています。
ひなどりクラスタ用のチャンネルで欲しいパッケージや機能を言うと鯖缶が時間があるときに導入したりしています。
間違えて鯖缶が人がログイン中のloginノードに再起動をかけてしまったときには謝罪をしたりもしています。
おわりに
横田研では自分たちで構築・運用したサーバの上で研究を行いたい学生を募集中です。 (もちろん、多数のスーパーコンピュータの利用も可能です)
愉快な鯖缶たちと横田先生
うおおおおお pic.twitter.com/1xxYzliwtH
— Yuichiro (@y1r96) January 29, 2021
▲DGX A100の納品を喜ぶ上野。

▲来年度のひなどりクラスタの増強方針を考える星野。
▲A6000を両手に喜ぶ大友。

 ▲DGX A100の納品を喜ぶ横田先生。
▲DGX A100の納品を喜ぶ横田先生。